
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- mysql
- 생각로그
- 자바스크립트
- Git
- mongoose
- javascript
- WIL
- til
- 리눅스
- MongoDB
- typescript
- 생각정리
- 기록
- 코테
- react
- nest.js
- Grafana
- mongo
- 알고리즘
- array
- js
- 주간회고
- 피드백
- 트러블슈팅
- next.js
- 네트워크
- Java
- 생각일기
- 회고
- CS
- Today
- Total
코딩일상
[자료구조] 배열(Array) 본문

1)자료구조를 들어가기 앞서
시간복잡도에 대해 간단히 짚고 넘어가고자 한다.
시간복잡도(TimeComplexity)
처음 이용어를 접했을때는 뭐 멍멍이 소리이지라고 생각을 하였다.
시간복잡도는 데이터구조의 오퍼레이션 혹은 알고리즘이 얼마나 빠르고, 느린지를 측정하는 방법이다.
이것은 실제 시간을 측정하는것은 아니다.
얼마나 많은 단계(step)이 있는지에 따라 구분한다 좀 더 자세한것은 따로 포스팅을 하겠다.
2)메모리 관점에서의 배열??
메모리의 종류는 2가지로 볼 수있다.
-휘발성(volatile) 메모리
ex)내 컴퓨터의 램(RAM: Random Access Memmory)
-비휘발성(non-volatile) 메모리
ex)내컴퓨터의 하드드라이브
여기서 잠깐?? 왜 램은 Random Access Memmory 일까?
램에 데이터를 저장하게되면 데이터의 주소가 부여된다.
예를 들아 10번에 Alex라는 데이터가 있다면 이를 찾아서 사용할때
1,2,3,4….9,10이렇게 순서대로 가서 데이터를 찾는게 아니라 MemoryAddress인 10번으로 가서 바로 데이터를
찾아오기에 램이 Random Access Memmory라고 불리는것이다.
그럼이제 진짜 본격적으로 가보자면, 배열은 어떻게 램에 있을까??
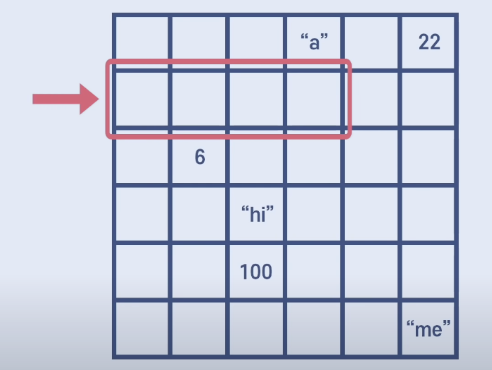
메모리에 배열이 들어갈경우 배열이 얼마나 긴 지를 설명 즉, 부여를 해주어야한다.
최대 4개의 공간이 필요하다면 위 그림같이 메모리에게 배열의 길이가 최대 4개야 라고 알려주어야 한다는것이다.
그런데 나는 JS만 아직 다루어보아서 그런것을 해본적이 없다.
그렇다. 이러한 배열의 길이가 최대가 얼마가될지 메모리에게 알려주는것을 JS 나Python기반이라면
이를 자동으로 핸들링을 해준다고 한다.
이를 자동으로 핸들링을 해줌으로써 개발자는 편한점도 있지만 그 덕분에 프로그램이 느려질수도있다.
(실제 계획보다 더 길게 핸들링을 해줄수도있기에)
3)배열은 그럼 어떻게 읽는가??(READ)
들어가기에 앞서 READ와 SEARCH는 다른개념이다.
READ: 데이터의 위치를 알고 그것을 그냥 읽는것이다.
SEARCH: 데이터의 위치를 모르고 원하는 데이터를 찾는것이다.

즉 그림과 같이 메모리의 박스에는 수많은 주소들이 부여되어있는데 원하는값을 찾으려면 그 박스를 열어야 값을 확인할수가있다.

즉 이렇데 4개의 값이 들어있는 배열형태의 데이터가 있는데
여기서 피자라는 데이터를 찾고싶으면 배열의 아이템 하나하나 찾아서 값을 열어보고 확인을 해야한다는 뜻이다.
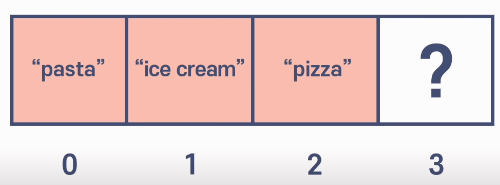
위 그림과같이 하나하나 열어서 ‘pizza’라는 값이 나올때 까지 하나하나 비교해서 찾아야하기에 그냥 읽는것 보다 속도가 오래걸린다.
이렇게 하나하나 값을 열어보고 찾는 과정을 우리는 선형검색(Linear Search)라고 한다.
순서대로 0부터 하나하나 끝까지 찾는것을 말한다.
4)배열의 데이터 추가??(INSERT, ADD)
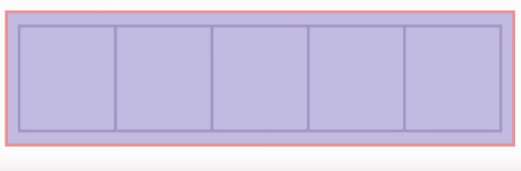
배열에 최대 5개의 데이터가 들어간다고 메모리에 명령을 사전에 해놓고
4개의 데이터가0,1,2,3으로 들어가있느 상황에서 추가로 데이터를 추가할경우 중요한것은
추가되어지는 데이터가 어디에?? 들어가냐는것이다.
4-1)4가지경우로 볼 수있다.
1)그냥 비어있던 공간에 데이터를 추가
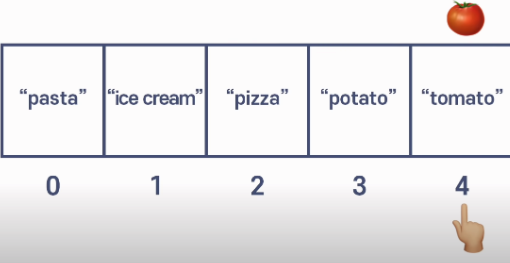
가장 베스트인상황은 이렇게 맨마지막에 비어있던 4번째 데이터 공간에 추가하게 되는것이다.
(즉, 그냥 비어있던 공간에 데이터를 추가만 하면 되는것)
2)배열 중간에 들어가게되는것

tomato가 배열 중간에 들어가게되는것이다.
그렇게 된다면 pizza, potato는 각각 오른쪽으로 데이터를 옮기고(그래야 ice cream옆에 빈공간이 생기게 때문)
3) 0번째에 데이터를 추가 해야하는경우

더 안좋은 시나리오의 경우에는 위와같이 0번째에 데이터를 추가 해야하는경우이다
모든데이터의 자리를 옮겨야 하기 때문이다.
4) 미리 할당되어있는 배열의 최대 길이에서 추가로 데이터를 담아야 하는경우

가장 최악의 시나리오는 미리 할당되어있는 배열의 최대 길이에서 추가로 데이터를 담아야 하는경우이다.
이미 5개(0~4)의 데이터가 할당이 되어있는데 배열에 데이터를 추가 하게될경우
6개의 배열을 메모리에 명령을하고 거기에 이전 데이터를 복사후 데이터를 추가 할 수있기 때문이다.
5)배열의 데이터 삭제??(DELETE)
삭제의 경우 배열에 뭔가를 추가하는것과 비슷하다.
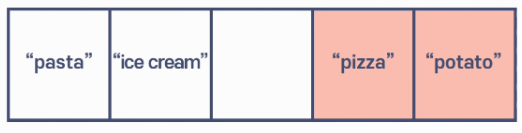
중간에서 데이터가 삭제될 경우 배열은 공백이 있으면 되지 않으니깐 그 공백을 채우기 위해서
위 그림에서는 pizza, potato가 왼쪽으로 각각 움직여주어야 한다. 그렇다면 더 안좋은건 … 예상하다 싶이

첫번째 데이터가 사라지게 되면 모든값이 한칸씩 움직여야 한다는 것이다.
6)결론
배열은 데이터를 읽을때(READ)는 아주 좋은 데이터 형태이다.
주소만 알면 그 주소로 바로 이동을 해서 데이터를 읽을수 있기 때문이다.
다만 그외 경우 느려질수있는경향이 있다는점을 요번기회에 알게 되었다.
- 검색(SEARCH)
- 추가(ADD)
- 삭제(DELETE)
그래도 만약 배열의 형태에서 추가나 삭제를 해야할경우에는 배열의 맨끝에서 하는것을 추천한다
'Study > CS' 카테고리의 다른 글
| [알고리즘] 버블, 선택, 삽입 정렬 알고리즘 (0) | 2022.11.21 |
|---|---|
| [알고리즘] 이진 검색과 선형 검색?? (1) | 2022.11.18 |
| [도입]데이터 구조와 알고리즘은 왜 배워야할까?? (0) | 2022.11.16 |
| 여러작업을 수행하는 애플리케이션,소프트웨어의 계층구조 (1) | 2022.08.13 |
| [CS스터디]고수준 언어에서 프로그램 실현까지!! (0) | 2022.08.04 |



